Connect Streamlit to Snowflake
Introduction
This guide explains how to securely access a Snowflake database from Streamlit Cloud. It uses the snowflake-connector-python library and Streamlit's secrets management.
Create a Snowflake database
Note
If you already have a database that you want to use, feel free to skip to the next step.
First, sign up for Snowflake and log into the Snowflake web interface (note down your username, password, and account identifier!):
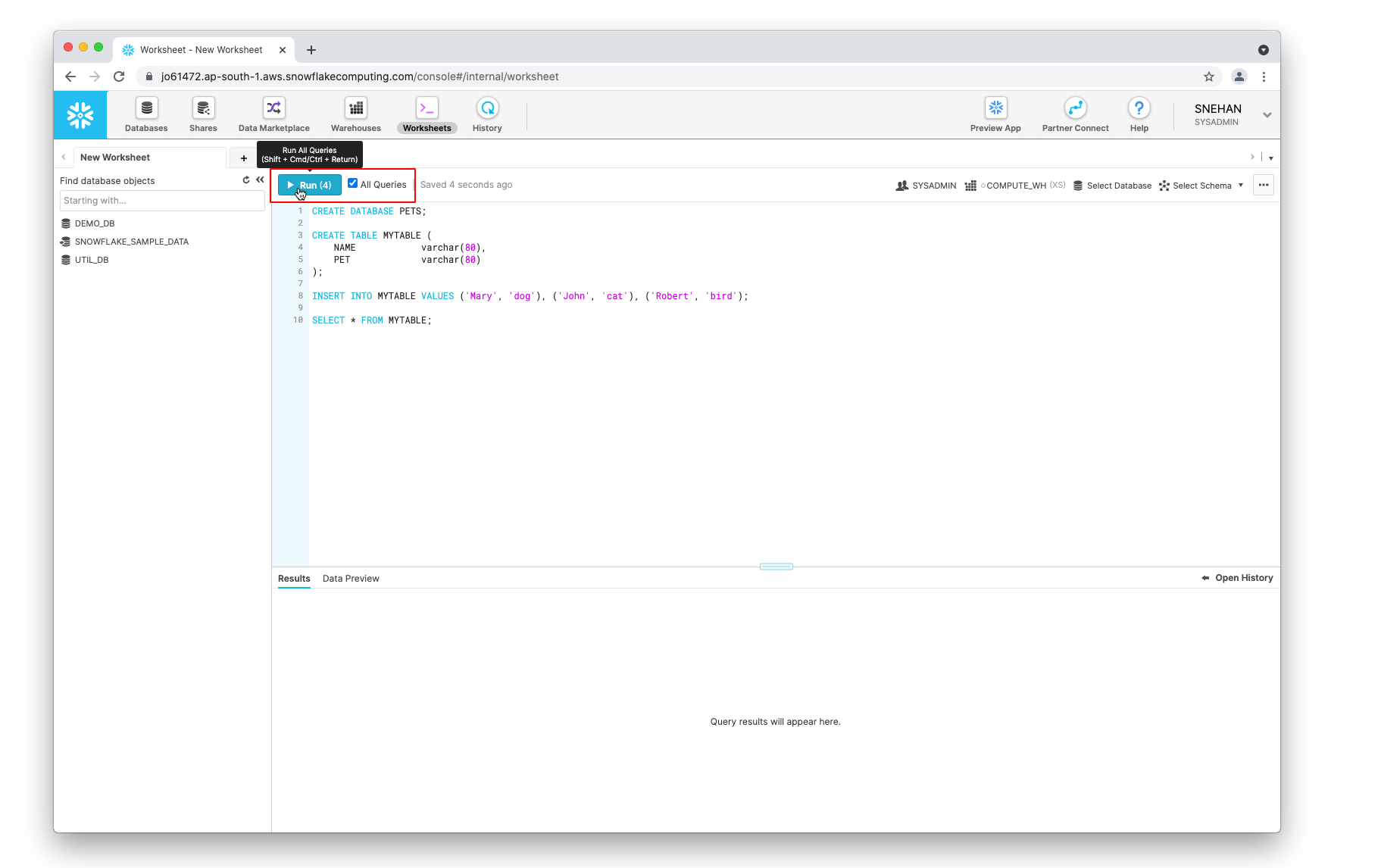
Enter the following queries into the SQL editor in the Worksheets page to create a database and a table with some example values:
CREATE DATABASE PETS;
CREATE TABLE MYTABLE (
NAME varchar(80),
PET varchar(80)
);
INSERT INTO MYTABLE VALUES ('Mary', 'dog'), ('John', 'cat'), ('Robert', 'bird');
SELECT * FROM MYTABLE;
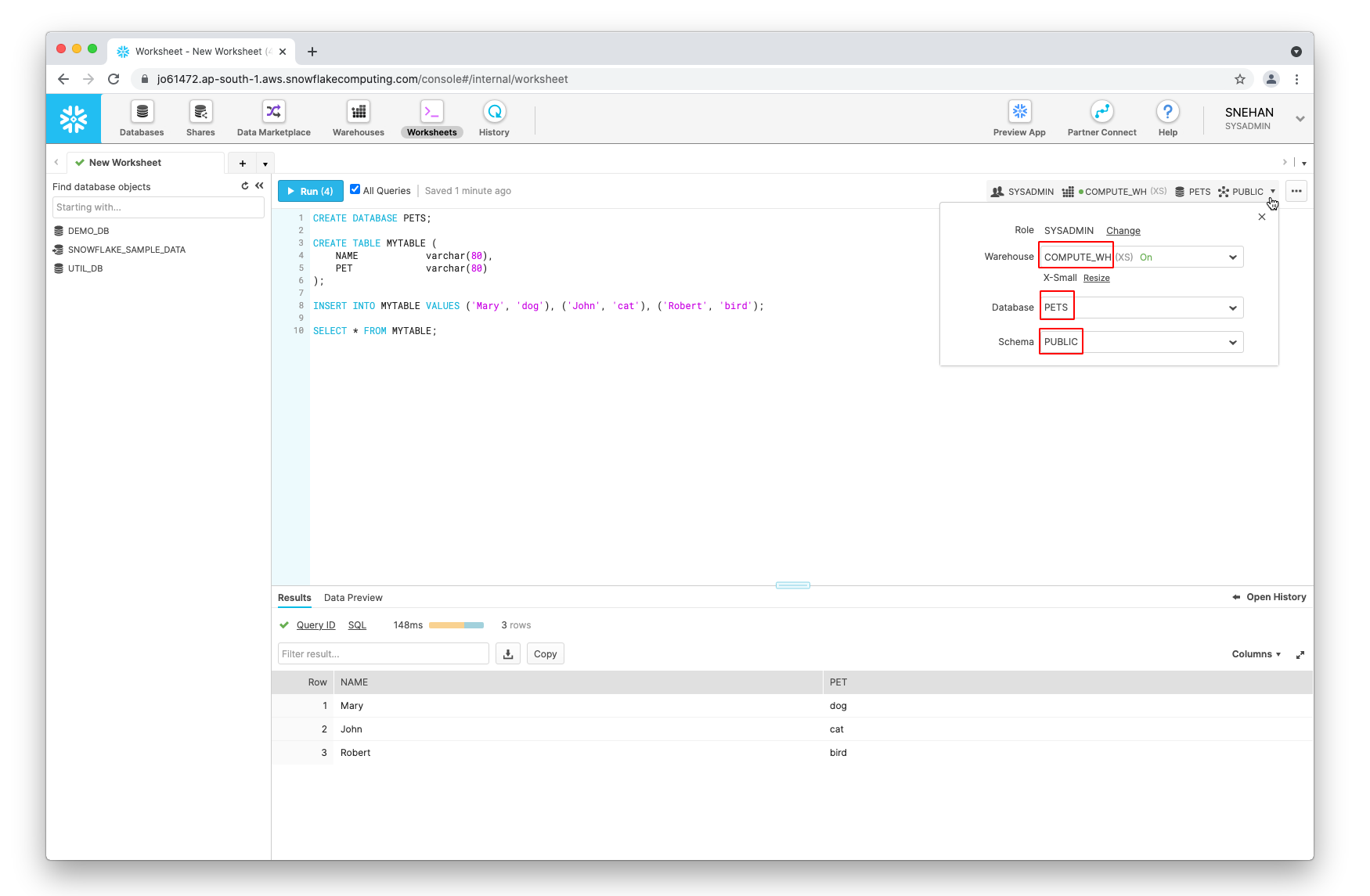
Select All Queries and click on Run to execute the queries. Make sure to note down the name of your warehouse, database, and schema from the dropdown menu on the same page:
Add username and password to your local app secrets
Your local Streamlit app will read secrets from a file .streamlit/secrets.toml in your app’s root directory. Create this file if it doesn’t exist yet and add your Snowflake username, password, account identifier, and the name of your warehouse, database, and schema as shown below:
# .streamlit/secrets.toml
[snowflake]
user = "xxx"
password = "xxx"
account = "xxx"
warehouse = "xxx"
database = "xxx"
schema = "xxx"
If you created the database from the previous step, the names of your database and schema are PETS and PUBLIC, respectively.
Important
Add this file to .gitignore and don't commit it to your Github repo!
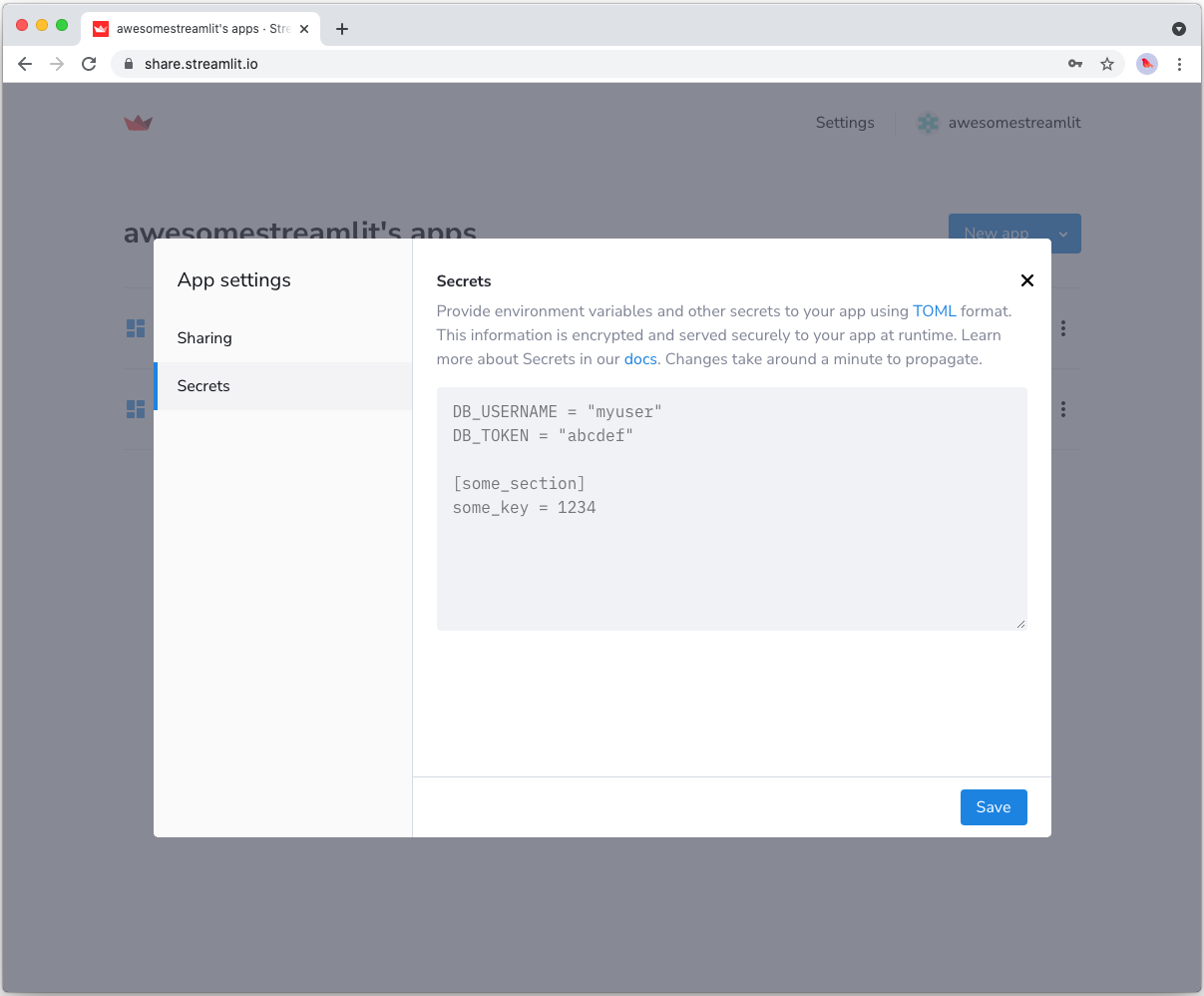
Copy your app secrets to the cloud
As the secrets.toml file above is not committed to Github, you need to pass its content to your deployed app (on Streamlit Cloud) separately. Go to the app dashboard and in the app's dropdown menu, click on Edit Secrets. Copy the content of secrets.toml into the text area. More information is available at Secrets Management.
Add snowflake-connector-python to your requirements file
Add the snowflake-connector-python package to your requirements.txt file, preferably pinning its version (replace x.x.x with the version you want installed):
# requirements.txt
snowflake-connector-python==x.x.x
Write your Streamlit app
Copy the code below to your Streamlit app and run it. Make sure to adapt query to use the name of your table.
# streamlit_app.py
import streamlit as st
import snowflake.connector
# Initialize connection.
# Uses st.cache to only run once.
@st.cache(allow_output_mutation=True, hash_funcs={"_thread.RLock": lambda _: None})
def init_connection():
return snowflake.connector.connect(**st.secrets["snowflake"])
conn = init_connection()
# Perform query.
# Uses st.cache to only rerun when the query changes or after 10 min.
@st.cache(ttl=600)
def run_query(query):
with conn.cursor() as cur:
cur.execute(query)
return cur.fetchall()
rows = run_query("SELECT * from mytable;")
# Print results.
for row in rows:
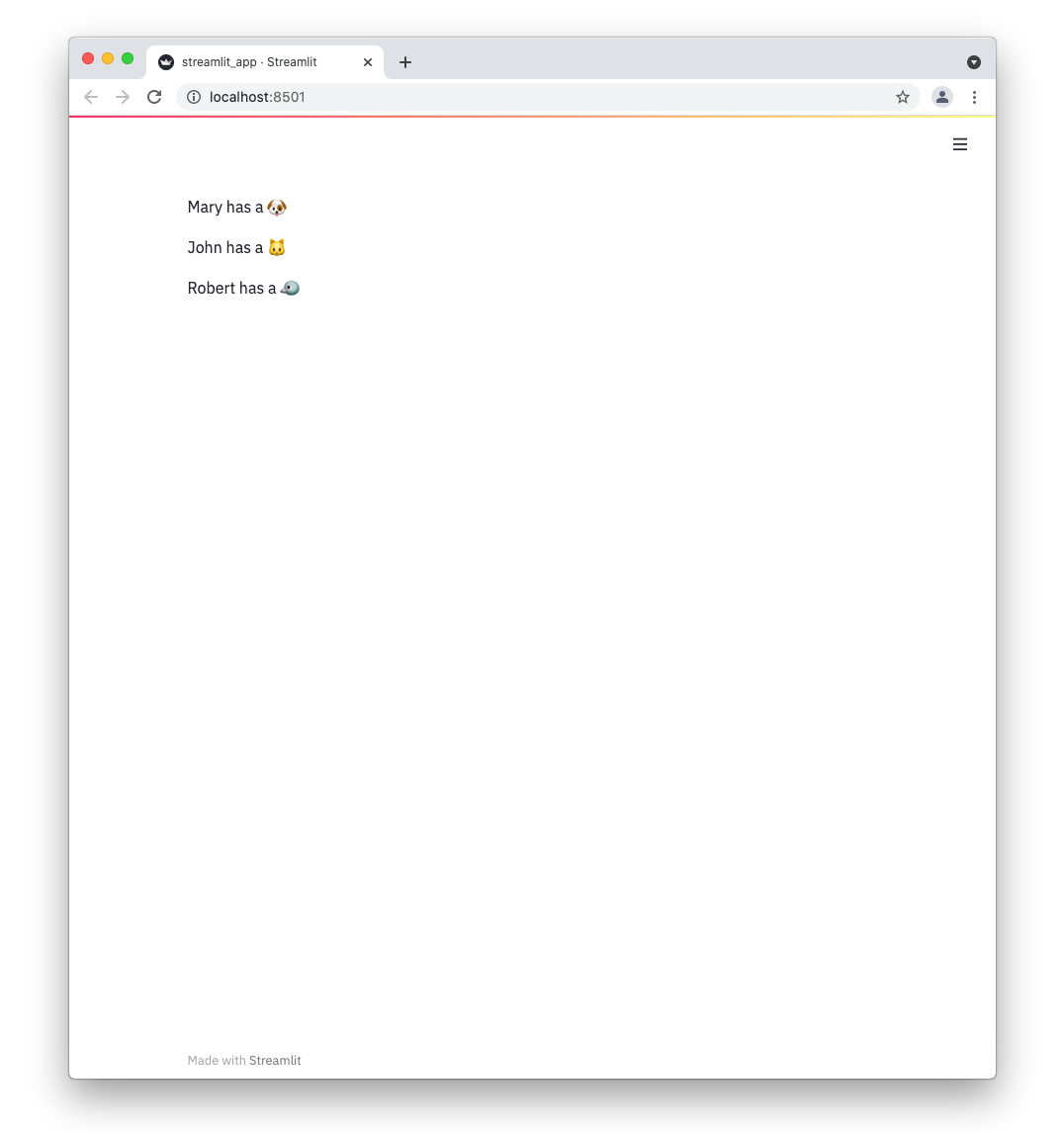
st.write(f"{row[0]} has a :{row[1]}:")
See st.cache above? Without it, Streamlit would run the query every time the app reruns (e.g. on a widget interaction). With st.cache, it only runs when the query changes or after 10 minutes (that's what ttl is for). Watch out: If your database updates more frequently, you should adapt ttl or remove caching so viewers always see the latest data. Read more about caching here.
If everything worked out (and you used the example table we created above), your app should look like this: